SECTION 10
Evaluation + Observability
Ground truth written before agents, not after.
Evaluation
| Stateful invalidation | 13/13 |
| Change detection | 100% |
| Routing accuracy | 89% |
| Policy compliance | 100% |
| Compound risk detection | 2/2 |
| Decision pack structure | 6/6 |
| Narrative faithfulness | PASS (LLM-as-judge) |
Ground truth written before agents, not after.
Observability
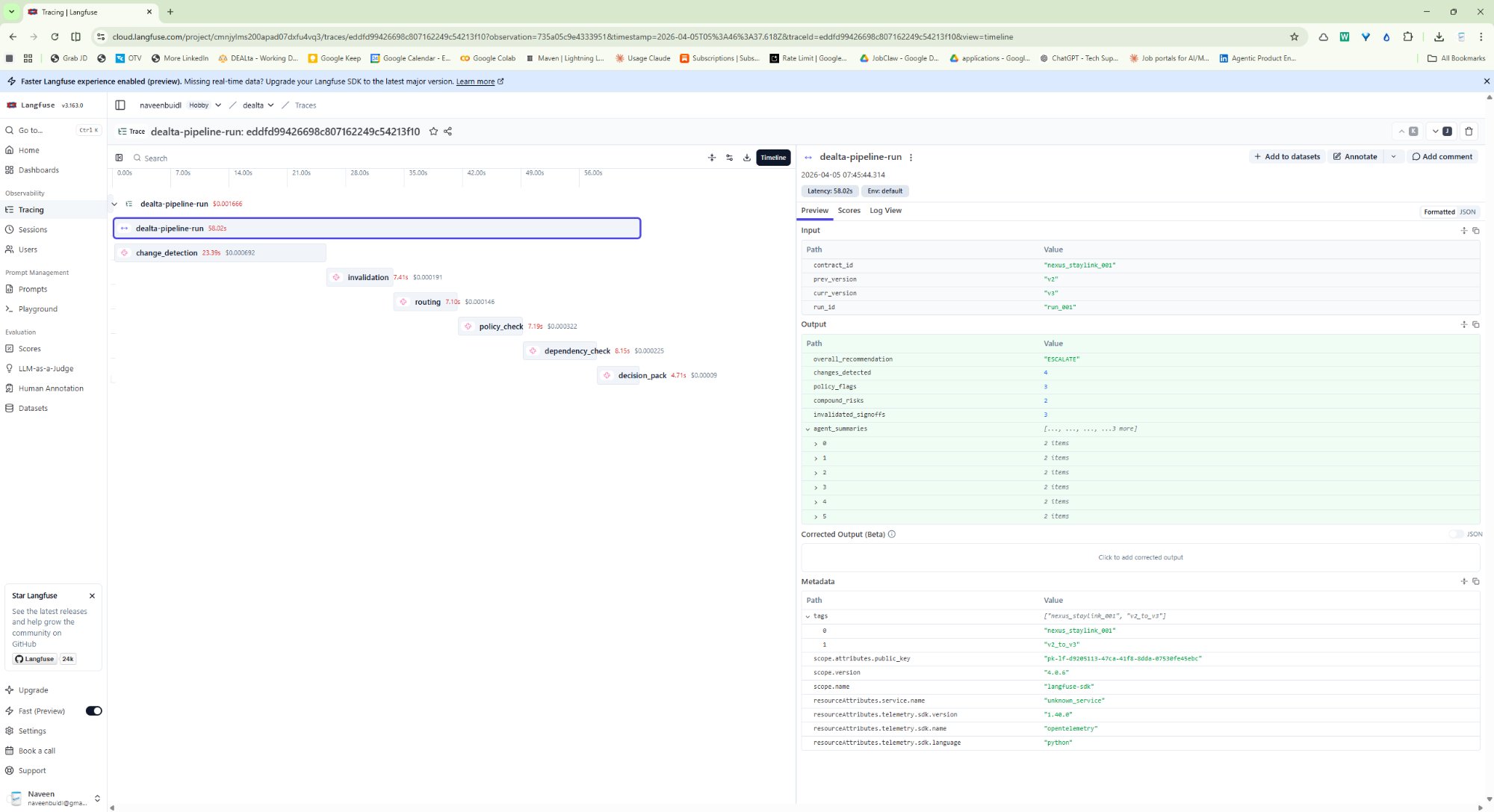
6 agent spans with per-step cost, latency, and I/O visibility
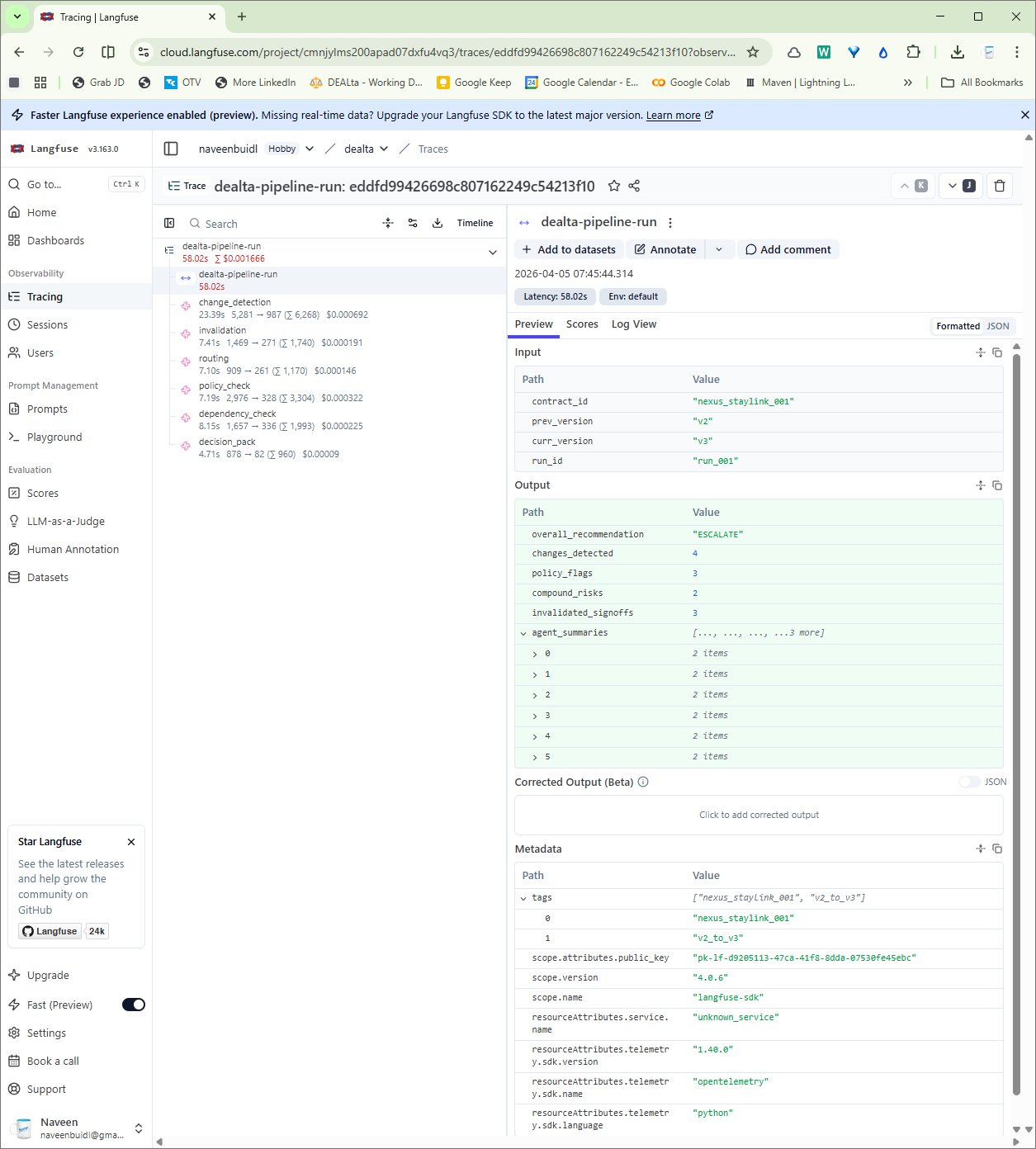
Pipeline audit: inputs, outputs, metadata
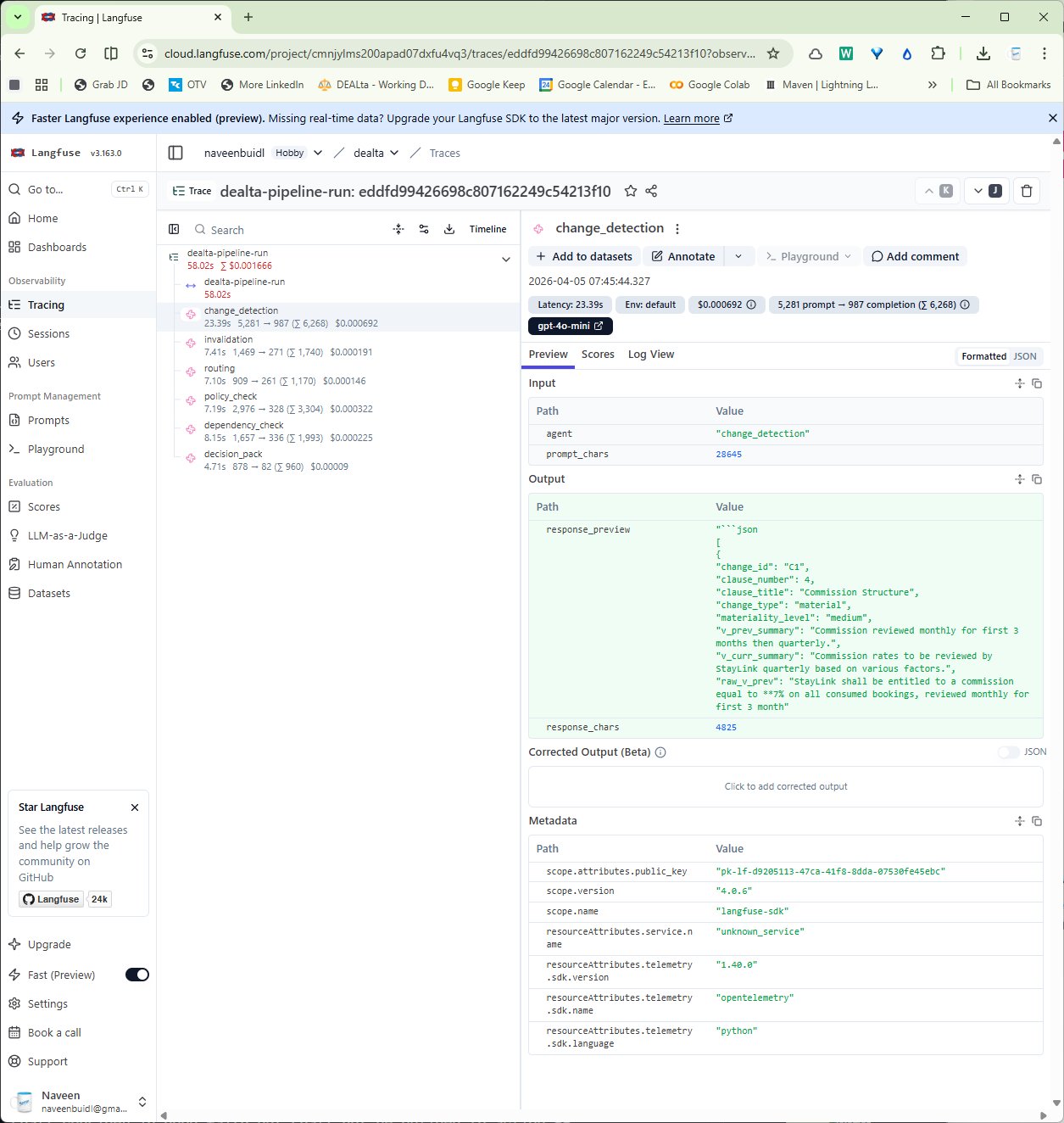
Agent detail: prompt, response, tokens
$0.0017/run · 58s total · 6 traced spans · gpt-4o-mini as eval judge